
Moin, mal wieder Absturzprobleme. Dh. der Server ist heute Morgen kommentarlos neu gestartet.
Zur betreffenden Zeit nichts unter /var/crash, ipmitool sel list oder dmesg
memtest läuft problemlos durch, Platten sind bei Zugriff selten über 40°C
Es passierte, während ich eine große Datenmenge von ihm kopierte (50Gb). Schon länger nicht mehr passiert, dass die Kiste bei längeren Kopiervorgängen wegsemmelte.
Ich habe das Netzteil daher in Verdacht. Entweder defekt oder unterdimensioniert (485W). Es wurde wegen Abstürzen dieser Art bisher ALLES (CPU, Board, RAM-Riegel, Festplatten, sogar neue Kühlpaste für CPU und SAS-Controller) getauscht. Nur eben noch nicht das NT, daher meine Vermutung.
Die Rechnung der Dimensionierung:
11 Watt pro SAS-Platte laut specs (8 Stück mit 15 Watt gerechnet) = 120
3x Sata gemischt (3 Stück mit 15 Watt gerechnet) = 45
CPU 95W TDP (nehm ich mal so als Wert)
6 Lüfter (mit guten 5W gerechnet) = 30
2 PCI-E Karten (1x DUALNIC, 1x SAS-Controller) = keine Ahnung, gönnen wir den beiden mal gute 20W zusammen
Bleiben fürs Mainboard und für einzelne Mehrleistung der Komponenten immer noch 175W übrig.
max. gemessener Stromverbrauch an der Dose 260W
Ich hab jetzt mal die Kiste offen ans dickere Netzteil gehängt wie auf dem Foto.
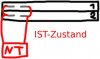
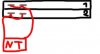
Es fällt mir noch ein, dass ich vielleicht die Backplane falsch verstromt habe. Wie schließt man die Backplane korrekt an? Wie im IST-Zustand oder eins der anderen Beispiele? (bin kein gimpmeister )
)
Zur betreffenden Zeit nichts unter /var/crash, ipmitool sel list oder dmesg
memtest läuft problemlos durch, Platten sind bei Zugriff selten über 40°C
Es passierte, während ich eine große Datenmenge von ihm kopierte (50Gb). Schon länger nicht mehr passiert, dass die Kiste bei längeren Kopiervorgängen wegsemmelte.
Ich habe das Netzteil daher in Verdacht. Entweder defekt oder unterdimensioniert (485W). Es wurde wegen Abstürzen dieser Art bisher ALLES (CPU, Board, RAM-Riegel, Festplatten, sogar neue Kühlpaste für CPU und SAS-Controller) getauscht. Nur eben noch nicht das NT, daher meine Vermutung.
Die Rechnung der Dimensionierung:
11 Watt pro SAS-Platte laut specs (8 Stück mit 15 Watt gerechnet) = 120
3x Sata gemischt (3 Stück mit 15 Watt gerechnet) = 45
CPU 95W TDP (nehm ich mal so als Wert)
6 Lüfter (mit guten 5W gerechnet) = 30
2 PCI-E Karten (1x DUALNIC, 1x SAS-Controller) = keine Ahnung, gönnen wir den beiden mal gute 20W zusammen
Bleiben fürs Mainboard und für einzelne Mehrleistung der Komponenten immer noch 175W übrig.
max. gemessener Stromverbrauch an der Dose 260W
Ich hab jetzt mal die Kiste offen ans dickere Netzteil gehängt wie auf dem Foto.
Es fällt mir noch ein, dass ich vielleicht die Backplane falsch verstromt habe. Wie schließt man die Backplane korrekt an? Wie im IST-Zustand oder eins der anderen Beispiele? (bin kein gimpmeister
)




")



")

